
Hallo,
welche Verfahren wende ich in SPSS an, wenn ich schauen möchte,
ob es bei 3 (unabhängigen) Gruppen signifikante Unterschiede gibt?
Im Datensatz habe ich relative Häufigkeiten (u.a.).
Anova fällt wegen nicht ganz normalverteilter Daten eher raus,
aber wenn ich das interessehalber trotzdem durchrechne, welcher
Post Hoc ist passend?
Bonferroni spuckt Signifikanzen von 1,0 aus, Scheffe war da bei 0,5.
Ich habe mal gelesen Tukey soll dem t-test ähnlich sein,
aber ich komme mit der Interpretation nicht zurecht.
Ich kann mit den Unterschieden nichts anfangen.
Kann mir jemand sagen, wie Kruskal zu interpretieren ist?
Das wird wohl der richtige Test für nicht NV Daten sein, bei 3 Gruppen.
Wenn ich für die rel. Häufigkeiten Chi² rechne, dann sind alle Zellen
unter 5 und da verstehe ich das Ergebnis gar nicht.
Gibt es eine Alternative?
VG
Anova, Kruskal oder Chi², Post-Hoc
7 Beiträge
• Seite 1 von 1
Anova, Kruskal oder Chi², Post-Hoc
![]() von Wolle » Mo 5. Okt 2015, 19:34
von Wolle » Mo 5. Okt 2015, 19:34
- Wolle
- Beiträge: 6
- Registriert: Mo 5. Okt 2015, 19:00
- Danke gegeben: 2
- Danke bekommen: 0 mal in 0 Post
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von ponderstibbons » Mo 5. Okt 2015, 20:47
von ponderstibbons » Mo 5. Okt 2015, 20:47
Anova fällt wegen nicht ganz normalverteilter Daten eher raus,
Für eine ANOVA müssen Daten nicht normalverteilt sein, allenfalls die Daten innerhalb von Gruppen bzw. die Residuen der ANOVA, Und auch das nur, wenn die Stichprobengröße gering ist.
aber wenn ich das interessehalber trotzdem durchrechne, welcher Post Hoc ist passend?
Vermutlich mehrere. Das hängt von den Umständen ab, z.B. ob man gleich große Gruppen hat oder eher konservativ oder liberal testen möchte.
Kann mir jemand sagen, wie Kruskal zu interpretieren ist?
Wieviel Vorwissen ist denn hinsichtlich Kruskal-Wallis vorhanden bzw. was brauchst Du noch zu wissen?
Wenn ich für die rel. Häufigkeiten Chi² rechne, dann sind alle Zellen unter 5 und da verstehe ich das Ergebnis gar nicht.
Gibt es eine Alternative?
Je nach Sachlage, also Thema/Fragestellung, Stichprobengröße, vorgenommenen Messungen etc.
VG
wtf
Mit freundlichen Grüßen
P.
- ponderstibbons
- Beiträge: 2528
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 2
- Danke bekommen: 257 mal in 256 Posts
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von Wolle » Di 6. Okt 2015, 15:02
von Wolle » Di 6. Okt 2015, 15:02
Hallo,
vielen Dank für die Antworten, das hat mir zum Teil schon weitergeholfen. Jetzt komme ich wenigstens wieder etwas voran. Ich hoffe sehr, noch
Jetzt komme ich wenigstens wieder etwas voran. Ich hoffe sehr, noch
weitere Hilfe zu bekommen.
Residuen habe ich noch nie berechnet, aber ich habe hoffentlich herausgefunden, wie es für die einzelnen Gruppen geht. Bevor alles wieder verschwindet, mache ich es kurz.
Das war über >univariate Analyse, wobei man eine einzelne AV eingibt und die entsprechende Fallgruppe auswählt >Speichern, standardisiert > in der Datenmatrix erscheint Spalte ZRE_1
>explorative Datenanalyse mit ZRE_1.
<<<Fazit nach meinem jetzigen Verständnis>>> Für jede einzelne Gruppe muss ich jede AV einzeln auf NV der Residuen testen.
Ergebnis: .019, bzw. Shapiro. 000, das heißt, die Residuen sind nicht normalverteilt. Q-Q Plot dazu sieht so aus:
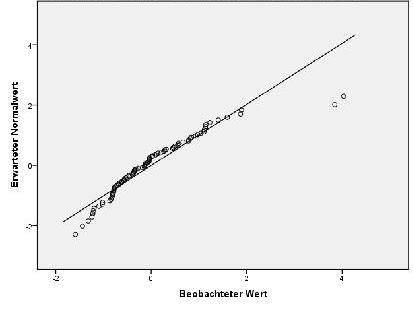
Der Signifikanz nach hätte ich mir das Bild anders vorgestellt...wesentlich stärker vom Normal abweichend.
Ich muss natürlich noch alle anderen AV, bzw. Residuen für jede Gruppe testen. Nichtparametrische Verfahren sind im Zweifel sicher eher zu wählen, als ein parametrisches, nehme ich an.
Wobei ich gelesen habe, dass eine ANOVA recht robust auf die Verletzung der NV reagieren soll.
Mit den Post Hoc Tests müsste ich nochmal schauen, welcher welche Voraussetzung hat, meine 3 Gruppen sind klein (je 10 Personen) und ich würde eher konserativ testen, aber ein liberaler Test wäre auch okay. Die Unterschiede könnten ja auch interessant sein.
Mal unabhängig davon:
Ich muss noch schauen, welche Voraussetzungen der t-test hat, denn wenn ich nur 2 geplante Vergleiche mache, dann dürfte es wegen der Fehlerkummulierung (?) weniger
das Problem sein, richtig?
Ich habe Kruskal nochmal gerechnet und folgendes gemacht:
>Analyse anpassen >AVs eingeben >Faktor eingeben >ANOVA nach Kruskal >Mehrfachvergeleiche
Für alle AVs soll die H0 behalten werden, 2 AVs sind kurz vor Signifikanzerreichung (.07)
Nun sieht es bei den beiden AVs so aus, als wäre gerade dort (bei einer von den drei Gruppen) eine große Varianz in den Werten. Könnte das dazu geführt haben, dass das Ergebnis daher nicht
signifikant geworden ist?
Wie berichte ich Kruskal korrekt, wenn ich folgende Werte bekomme: df(2) - 5,138 - p=.070
Die Übersichtstabelle ist wohl nicht so wichtig. Ich habe jetzt erst entdeckt, dass man auch noch Boxplots ausgegeben bekommt. Von daher habe ich nur noch folgende Fragen dazu:
Was heißt das "Teststatistik wird auf Bindungen angepasst" und wenn meine Hypothesen gerichtet sind, macht es dann etwas aus, dass der Test 2 seitig ist?
Alle Hypothesen sind in die Richtung:
Gruppe B und C haben längere Zeiten für XY, im Vergleich zur Gruppe A
Gruppe B und C zeigen eine häufigere Reaktion von Z, im Vergleich zur Gruppe A
Die genannten Effekte sind für C größer, im Vergleich zu B.
Also prinzipiell C>B>A.
Gewähltes Signifikanzniveau ist immer 0.05.
Noch zu Chi² und ich hoffe diese Angaben reichen, ansonsten bitte nochmal nachhaken.
Ich habe eine AV, die in Form relativer Häufigkeiten vorliegt (also 0,2 usw.). Damit soll ausgedrückt werden, wie "wahrscheinlich" das erneute Auftreten einer vorher gezeigten Reaktion
ist. Von der aufgetreten Reaktion habe ich aber keine Zahlen vorliegen, wie oft das Verhalten aufgetreten ist, sondern nur wie lange, also ein Zeitmaß. Praktisch unter der Aussage, je länger ein gezeigtes Verhalten auftritt, desto größer ist die Wahrscheinlichkeit, dass es erneut auftritt.
Ich müsste also wissen, wie ich dieses Häufigkeits-Maß überhaupt in SPSS analysiere. Muss ich es anders berechnen oder kann ich es, wie alle anderen AVs behandeln?
Mit Chi² und Kreuztabelle komme ich nicht weiter oder zurecht.
Danke schonmal für die Hilfe.
Viele Grüße (VG)
vielen Dank für die Antworten, das hat mir zum Teil schon weitergeholfen.
weitere Hilfe zu bekommen.
Residuen habe ich noch nie berechnet, aber ich habe hoffentlich herausgefunden, wie es für die einzelnen Gruppen geht. Bevor alles wieder verschwindet, mache ich es kurz.
Das war über >univariate Analyse, wobei man eine einzelne AV eingibt und die entsprechende Fallgruppe auswählt >Speichern, standardisiert > in der Datenmatrix erscheint Spalte ZRE_1
>explorative Datenanalyse mit ZRE_1.
<<<Fazit nach meinem jetzigen Verständnis>>> Für jede einzelne Gruppe muss ich jede AV einzeln auf NV der Residuen testen.
Ergebnis: .019, bzw. Shapiro. 000, das heißt, die Residuen sind nicht normalverteilt. Q-Q Plot dazu sieht so aus:
Der Signifikanz nach hätte ich mir das Bild anders vorgestellt...wesentlich stärker vom Normal abweichend.
Ich muss natürlich noch alle anderen AV, bzw. Residuen für jede Gruppe testen. Nichtparametrische Verfahren sind im Zweifel sicher eher zu wählen, als ein parametrisches, nehme ich an.
Wobei ich gelesen habe, dass eine ANOVA recht robust auf die Verletzung der NV reagieren soll.
Mit den Post Hoc Tests müsste ich nochmal schauen, welcher welche Voraussetzung hat, meine 3 Gruppen sind klein (je 10 Personen) und ich würde eher konserativ testen, aber ein liberaler Test wäre auch okay. Die Unterschiede könnten ja auch interessant sein.
Mal unabhängig davon:
Ich muss noch schauen, welche Voraussetzungen der t-test hat, denn wenn ich nur 2 geplante Vergleiche mache, dann dürfte es wegen der Fehlerkummulierung (?) weniger
das Problem sein, richtig?
Ich habe Kruskal nochmal gerechnet und folgendes gemacht:
>Analyse anpassen >AVs eingeben >Faktor eingeben >ANOVA nach Kruskal >Mehrfachvergeleiche
Für alle AVs soll die H0 behalten werden, 2 AVs sind kurz vor Signifikanzerreichung (.07)
Nun sieht es bei den beiden AVs so aus, als wäre gerade dort (bei einer von den drei Gruppen) eine große Varianz in den Werten. Könnte das dazu geführt haben, dass das Ergebnis daher nicht
signifikant geworden ist?
Wie berichte ich Kruskal korrekt, wenn ich folgende Werte bekomme: df(2) - 5,138 - p=.070
Die Übersichtstabelle ist wohl nicht so wichtig. Ich habe jetzt erst entdeckt, dass man auch noch Boxplots ausgegeben bekommt. Von daher habe ich nur noch folgende Fragen dazu:
Was heißt das "Teststatistik wird auf Bindungen angepasst" und wenn meine Hypothesen gerichtet sind, macht es dann etwas aus, dass der Test 2 seitig ist?
Alle Hypothesen sind in die Richtung:
Gruppe B und C haben längere Zeiten für XY, im Vergleich zur Gruppe A
Gruppe B und C zeigen eine häufigere Reaktion von Z, im Vergleich zur Gruppe A
Die genannten Effekte sind für C größer, im Vergleich zu B.
Also prinzipiell C>B>A.
Gewähltes Signifikanzniveau ist immer 0.05.
Noch zu Chi² und ich hoffe diese Angaben reichen, ansonsten bitte nochmal nachhaken.
Ich habe eine AV, die in Form relativer Häufigkeiten vorliegt (also 0,2 usw.). Damit soll ausgedrückt werden, wie "wahrscheinlich" das erneute Auftreten einer vorher gezeigten Reaktion
ist. Von der aufgetreten Reaktion habe ich aber keine Zahlen vorliegen, wie oft das Verhalten aufgetreten ist, sondern nur wie lange, also ein Zeitmaß. Praktisch unter der Aussage, je länger ein gezeigtes Verhalten auftritt, desto größer ist die Wahrscheinlichkeit, dass es erneut auftritt.
Ich müsste also wissen, wie ich dieses Häufigkeits-Maß überhaupt in SPSS analysiere. Muss ich es anders berechnen oder kann ich es, wie alle anderen AVs behandeln?
Mit Chi² und Kreuztabelle komme ich nicht weiter oder zurecht.
Danke schonmal für die Hilfe.
Viele Grüße (VG)
- Wolle
- Beiträge: 6
- Registriert: Mo 5. Okt 2015, 19:00
- Danke gegeben: 2
- Danke bekommen: 0 mal in 0 Post
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von ponderstibbons » Di 6. Okt 2015, 17:15
von ponderstibbons » Di 6. Okt 2015, 17:15
Wobei ich gelesen habe, dass eine ANOVA recht robust auf die Verletzung der NV reagieren soll.
Normalverteilung ist für die Gültigkeit des F-Tests bzw. t-Tests irrelevant, wenn die Stichprobe groß genug ist.
Nun sieht es bei den beiden AVs so aus, als wäre gerade dort (bei einer von den drei Gruppen) eine große Varianz in den Werten. Könnte das dazu geführt haben, dass das Ergebnis daher nicht
signifikant geworden ist?
Beim Kruskal-Wallis gibt es keine Varianz, das ist ein Verfahren für Rangdaten (ordinale Daten).
wenn meine Hypothesen gerichtet sind, macht es dann etwas aus, dass der Test 2 seitig ist?
Das eine ist unabhängig vom anderen. http://www.uni-graz.at/ilona.papousek/t ... s/faq.html FAQ #3
Noch zu Chi² und ich hoffe diese Angaben reichen, ansonsten bitte nochmal nachhaken.
Ich habe eine AV, die in Form relativer Häufigkeiten vorliegt (also 0,2 usw.). Damit soll ausgedrückt werden, wie "wahrscheinlich" das erneute Auftreten einer vorher gezeigten Reaktion ist.
Wenn jede Person einen Wert wie 0,2 oder dergleichen hat, ist das keine kategoriale Variable, also kein Fall für einen Chi².
Mit freundlichen Grüßen
P.
- ponderstibbons
- Beiträge: 2528
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 2
- Danke bekommen: 257 mal in 256 Posts
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von Wolle » Mi 7. Okt 2015, 16:46
von Wolle » Mi 7. Okt 2015, 16:46
Guten Tag,
vielen Dank für die Antworten.
Ich kann nicht genau einschätzen, ob meine Gruppengröße von je 10 Personen ausreicht,
aber nun gut. Ich muss nehmen, was ich habe.
Chi² nicht rechnen zu müssen soll mir nur recht sein.
Soweit sollten meine Fragen dann erstmal geklärt sein,
herzlichen Dank.
Viele Grüße
Wolle
vielen Dank für die Antworten.
Normalverteilung ist für die Gültigkeit des F-Tests bzw. t-Tests irrelevant, wenn die Stichprobe groß genug ist.
Ich kann nicht genau einschätzen, ob meine Gruppengröße von je 10 Personen ausreicht,
aber nun gut. Ich muss nehmen, was ich habe.
Chi² nicht rechnen zu müssen soll mir nur recht sein.
Soweit sollten meine Fragen dann erstmal geklärt sein,
herzlichen Dank.
Viele Grüße
Wolle
- Wolle
- Beiträge: 6
- Registriert: Mo 5. Okt 2015, 19:00
- Danke gegeben: 2
- Danke bekommen: 0 mal in 0 Post
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von ponderstibbons » Mi 7. Okt 2015, 22:42
von ponderstibbons » Mi 7. Okt 2015, 22:42
Ich kann nicht genau einschätzen, ob meine Gruppengröße von je 10 Personen ausreicht,
Ich hatte schon die Befürchtung, dass ich noch ein drittes Mal das Thema ansprechen muss, bis diese für jede Statistik essenzielle Angabe kommt. Wenn die Gesamtstichprobe < 30 ist, dann geht man davon aus, dass der zentrale Grenzwertsatz nicht mehr sicherstellt, dass auch Stichproben aus nicht-normal verteilten Grundgesamtheiten valide Testergebnisse erbringen. Dann sind "nichtparametrische" Verfahren häufig die zuverlässige Alternative, auch wenn sie etwas anderes testen als t-Test oder Varianzanalyse, welche Mittelwerte vergleichen.
Mit freundlichen Grüßen
P.
- ponderstibbons
- Beiträge: 2528
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 2
- Danke bekommen: 257 mal in 256 Posts
Re: Anova, Kruskal oder Chi², Post-Hoc
![]() von Wolle » Do 8. Okt 2015, 18:28
von Wolle » Do 8. Okt 2015, 18:28
Guten Abend,
vielen herzlichen Dank für die Antwort.
Hatte ich vergessen anzugeben, dass ich 30 Personen in meiner Stichprobe habe?
Kann sein, dass ich 3 x 10 geschrieben habe und das untergegangen ist, da ich so viele Fragen hatte
und meine Beiträge so lang wurden.
Ich hatte das mit dem <30 schon gelesen, mich aber zu schnell von anderen Meinungen dazu,
Diskussionen, Beiträgen im Netz usw. abbringen lassen und dachte am Ende, 10 pro Gruppe
(30 ingesamt) sind schon sehr an der Grenze, da manche von 50 pro Stichprobe schrieben.
Danke auch nochmal für den letzten Satz, dann weiß ich, was ich mir auch zu Gemüte
führen sollte.
Vielen Dank für die Geduld.
Viele Grüße
Wolle
vielen herzlichen Dank für die Antwort.
Hatte ich vergessen anzugeben, dass ich 30 Personen in meiner Stichprobe habe?
Kann sein, dass ich 3 x 10 geschrieben habe und das untergegangen ist, da ich so viele Fragen hatte
und meine Beiträge so lang wurden.
Ich hatte das mit dem <30 schon gelesen, mich aber zu schnell von anderen Meinungen dazu,
Diskussionen, Beiträgen im Netz usw. abbringen lassen und dachte am Ende, 10 pro Gruppe
(30 ingesamt) sind schon sehr an der Grenze, da manche von 50 pro Stichprobe schrieben.
Danke auch nochmal für den letzten Satz, dann weiß ich, was ich mir auch zu Gemüte
führen sollte.
Vielen Dank für die Geduld.
Viele Grüße
Wolle
- Wolle
- Beiträge: 6
- Registriert: Mo 5. Okt 2015, 19:00
- Danke gegeben: 2
- Danke bekommen: 0 mal in 0 Post
7 Beiträge
• Seite 1 von 1
Zurück zu Tests und Gruppenvergleiche
Wer ist online?
Mitglieder in diesem Forum: Bing [Bot] und 0 Gäste